D4:基于文本引导扩散模型的域自适应数据增强,用于葡萄园苗检测
发布时间:
2024-10-27
来源:
作者:
在农业领域,利用目标检测模型进行植物表型分析正受到人们的关注。植物表型是一种从图像中准确测量栽培作物质量和状况的技术,有助于提高作物产量和质量,减少对环境的影响。然而,由于标注的困难和领域的多样性,收集创建通用和高精度模型所需的训练数据是极具挑战性的。这种困难源于植物独特的形状和背景,以及由于环境条件和生长阶段而导致的外观显著变化。此外,很难在不同作物之间传输训练数据,尽管已经开发出对特定环境、条件或作物有效的机器学习模型,但它们无法广泛应用于实际领域。在葡萄园的嫩枝探测任务中面临着这样的挑战。因此,在本研究中,提出一种生成式人工智能数据增强方法(D4)。D4使用预先训练好的文本引导扩散模型,该模型基于从无人地面车辆或其他方式采集的视频数据中剔除的大量原始图像,以及少量带注释的数据集。该方法生成具有适应目标域的背景信息的新注释图像,同时保留目标检测所需的注释信息。此外,D4还克服了农业训练数据缺乏的问题,包括标注困难和域的多样性。我们证实,这种生成数据增强方法将BBox检测任务的平均精度提高了28.65%,将关键点检测任务的平均精度提高了13.73%。D4生成数据增强有望同时解决农业培训数据生成的成本和领域多样性问题,并提高检测模型的泛化性能。
 图1 葡萄园栽培注释任务的挑战。(a)极小花序的检测和计数;(b)茎部检测中的形状复杂性和部分遮挡;(c)白天拍摄的图像中背景植被和类似纹理的影响。
图1 葡萄园栽培注释任务的挑战。(a)极小花序的检测和计数;(b)茎部检测中的形状复杂性和部分遮挡;(c)白天拍摄的图像中背景植被和类似纹理的影响。
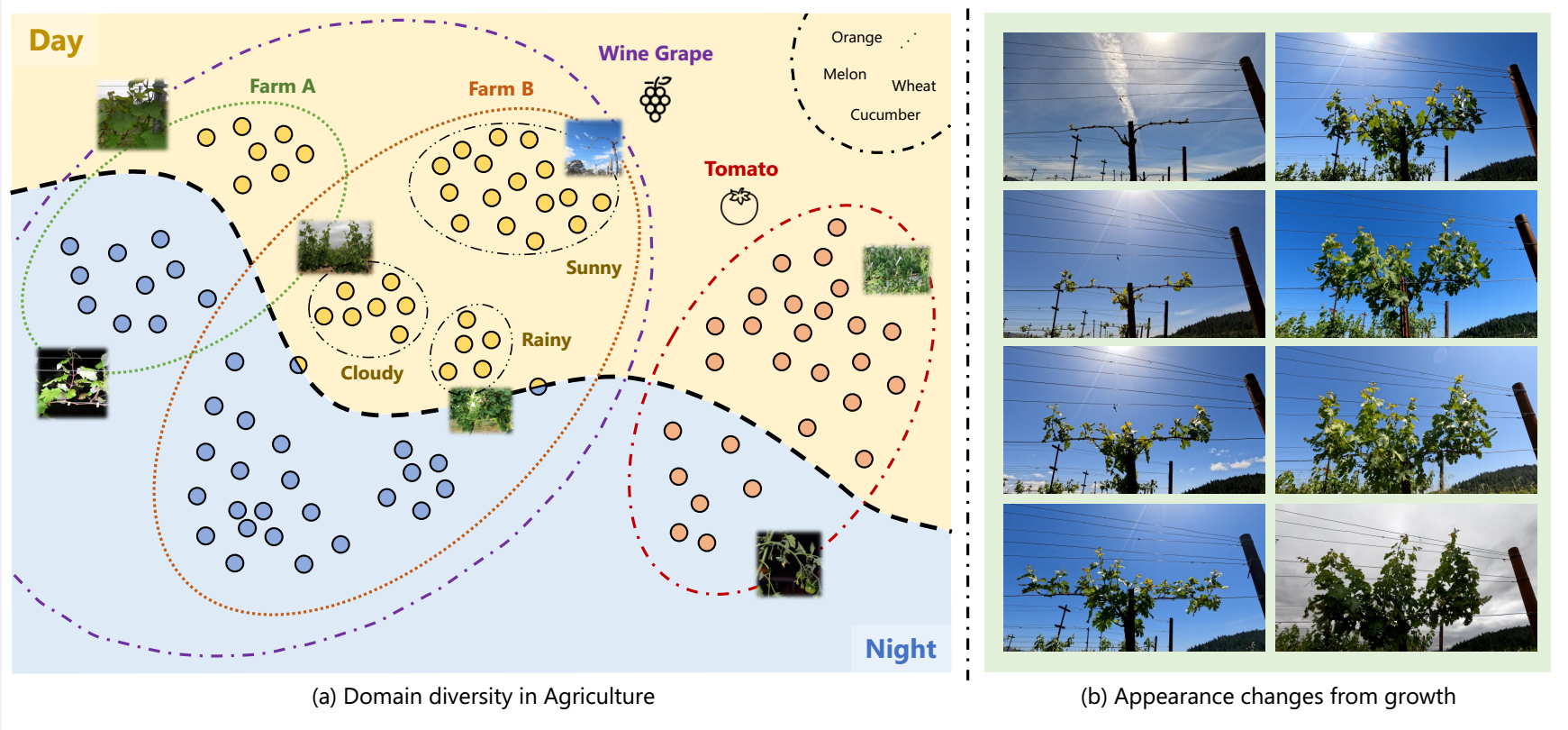 图2 农业领域多样性的挑战。(a)农业领域的领域多样性;(b)归因于植物生长的外观特征变化。
图2 农业领域多样性的挑战。(a)农业领域的领域多样性;(b)归因于植物生长的外观特征变化。
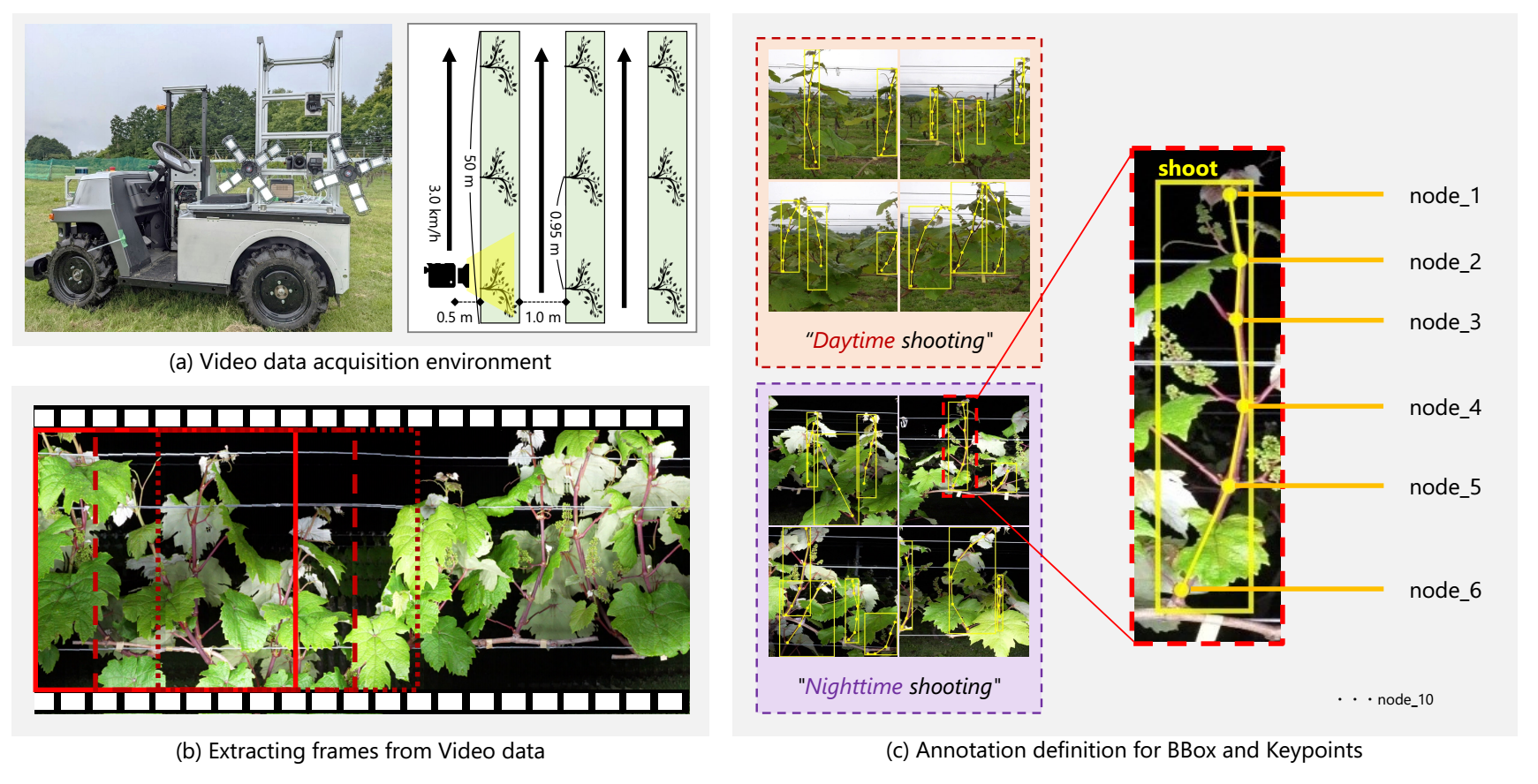 图3 本研究使用的数据集概述。(a)数据采集环境;(b)视频数据的帧提取;(c) BBox和关键点标注定义。
图3 本研究使用的数据集概述。(a)数据采集环境;(b)视频数据的帧提取;(c) BBox和关键点标注定义。
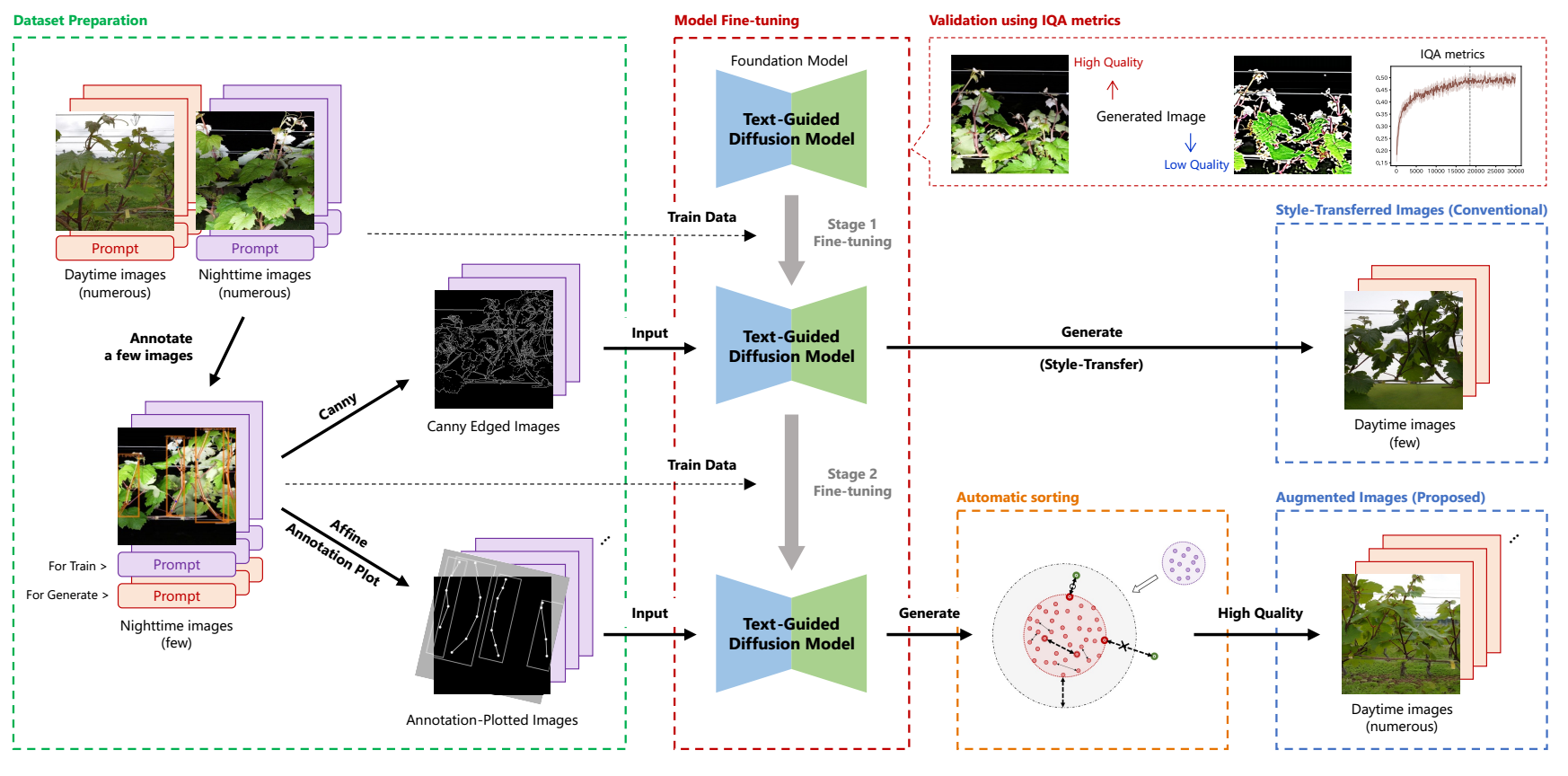 图4 D4的基本框架和关键组件。
图4 D4的基本框架和关键组件。
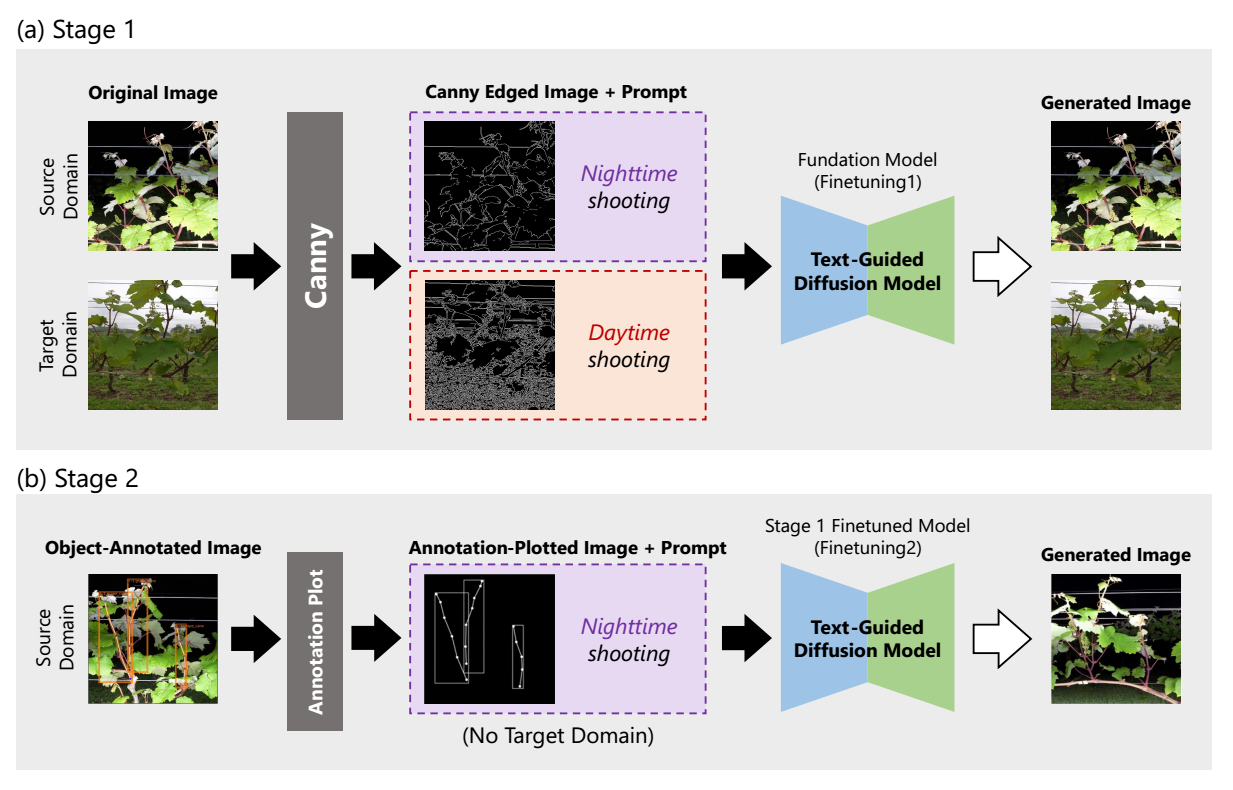 图5 预训练文本引导扩散模型。(a)阶段1:学习专有数据集中的广泛特征;(b)阶段2:学习专有数据集中的局部特征。
图5 预训练文本引导扩散模型。(a)阶段1:学习专有数据集中的广泛特征;(b)阶段2:学习专有数据集中的局部特征。
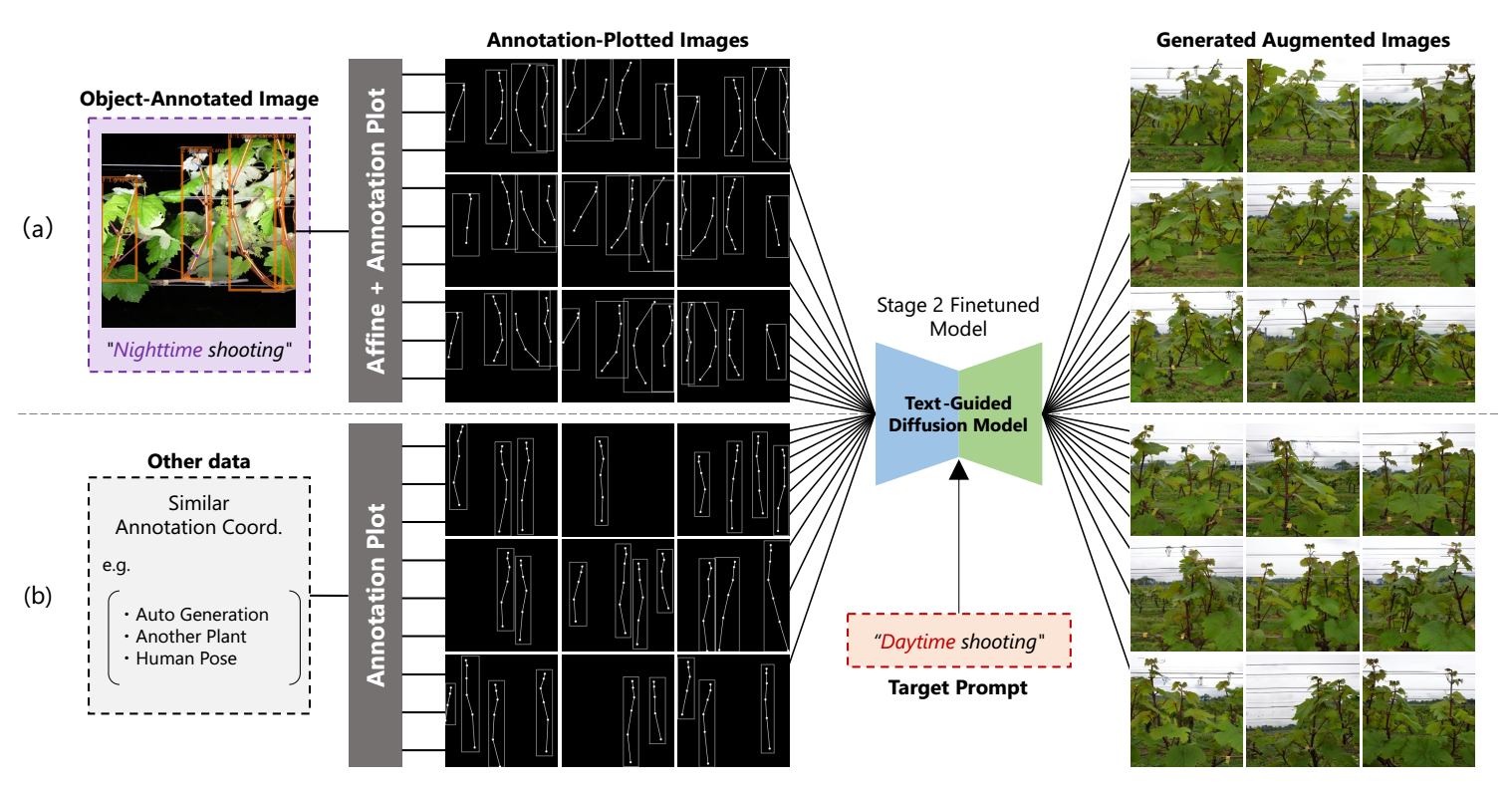 图6 使用预训练的文本引导扩散模型通过图像生成数据增强。(a)从一张夜间物体注释图像生成九张白天物体注释图像;(b)从类似的注释坐标信息生成白天物体注释图像。
图6 使用预训练的文本引导扩散模型通过图像生成数据增强。(a)从一张夜间物体注释图像生成九张白天物体注释图像;(b)从类似的注释坐标信息生成白天物体注释图像。
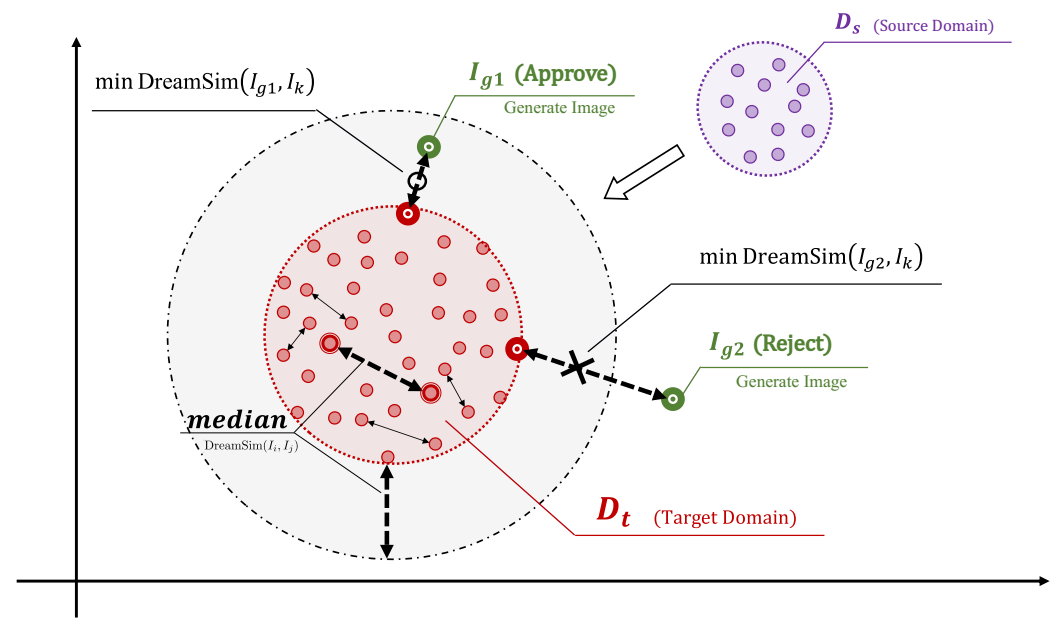 图7 使用DreamSim生成图像的自动选择机制。
图7 使用DreamSim生成图像的自动选择机制。
 图8 第二阶段预训练生成ControlNet模型的结果。
图8 第二阶段预训练生成ControlNet模型的结果。
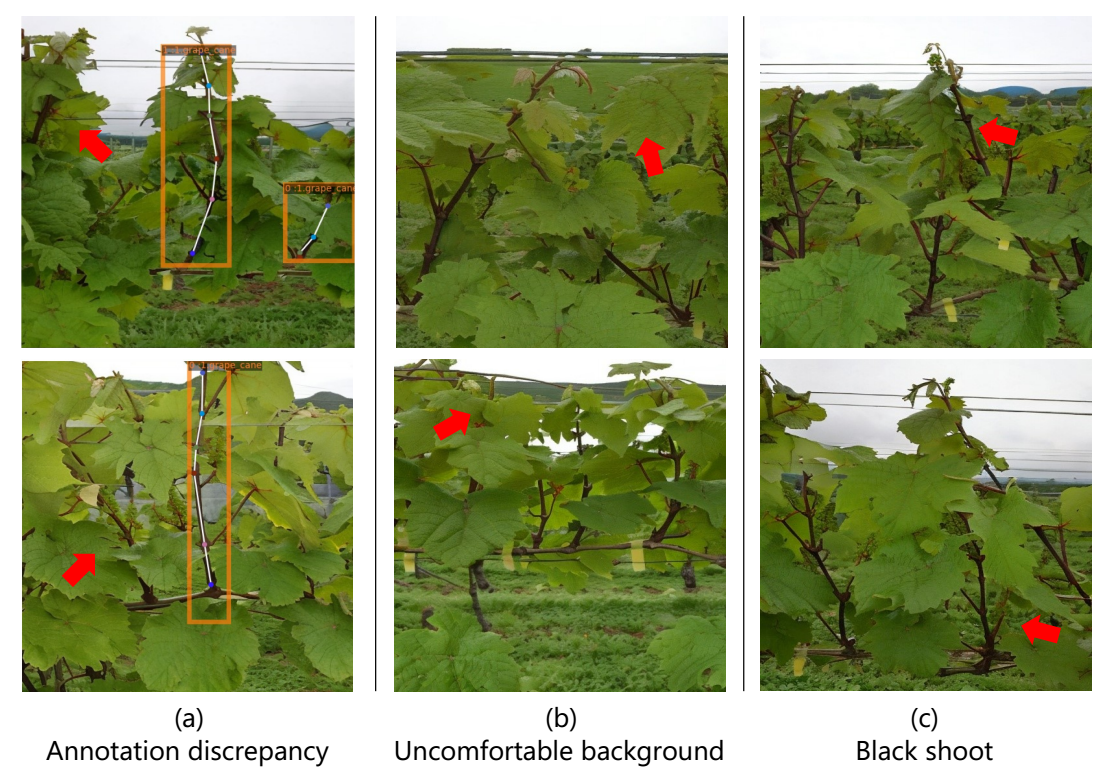 图9 被定性为质量差的生成图像示例。(a)注释差异;(b)不舒服的背景;(c)黑拍。
图9 被定性为质量差的生成图像示例。(a)注释差异;(b)不舒服的背景;(c)黑拍。
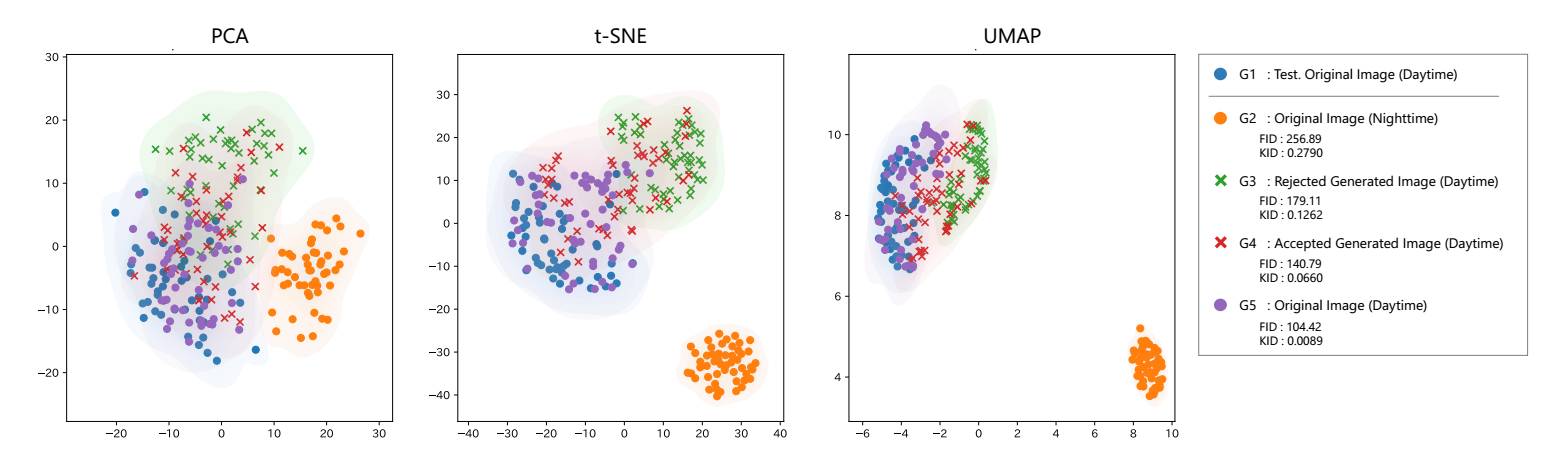 图10 通过降维实现图像特征分布的可视化。
图10 通过降维实现图像特征分布的可视化。
 图11 提示工程中基于人的感性判断的定性评价。
图11 提示工程中基于人的感性判断的定性评价。
Kentaro Hirahara, Chikahito Nakane, Hajime Ebisawa, Tsuyoshi Kuroda, Yohei Iwaki, Tomoyoshi Utsumi, Yuichiro Nomura, Makoto Koike, Hiroshi Mineno. (2024). D4: Text-guided diffusion model-based domain adaptive data augmentation for vineyard shoot detection. https://arxiv.org/pdf/2409.04060.
编辑
王春颖
推荐新闻

视频展示
联系我们
江南平台app体育
地址:北京市海淀区西三旗街道建材城中路12号院8号楼2门
电话:010-62925490、82928854、82928864、82928874、18600875228
传真:010-62925490-802
Email: info@phenotrait.com
邮编:100096
在线留言
关注我们
植物表型圈
植物表型资讯